L’analyse de logs SEO consiste à lire les fichiers journaux de ton serveur web pour comprendre exactement quels robots visitent ton site, à quelle fréquence, et ce qu’ils y font. En 2026, ce n’est plus seulement Googlebot qu’il faut surveiller : GPTBot, ClaudeBot, PerplexityBot et le tout nouveau Google-Agent (qui interagit avec ton site comme un humain) changent la donne. Concrètement, un site mal optimisé peut gaspiller jusqu’à 60% de son budget de crawl sur des URL inutiles. L’analyse de logs, c’est la seule source de données brutes qui te montre la réalité du terrain.
L’analayse de logs c’est quoi ?
Tu te demandes pourquoi certaines de tes pages mettent des semaines à être indexées alors que d’autres apparaissent en quelques heures ? Ou pourquoi ton contenu stratégique n’est jamais cité par ChatGPT ou Perplexity ? La réponse se trouve dans un endroit que 90% des sites ne regardent jamais : les fichiers log de leur serveur.
L’analyse de logs SEO, c’est grosso modo la radiographie de ton site vu par les robots. Pas les données filtrées de Google Analytics, pas les échantillons de la Google Search Console. Les données brutes, complètes, non censurées. Chaque requête HTTP, chaque passage de bot, chaque code de réponse du serveur. C’est la seule façon de savoir avec certitude ce qui se passe sur ton site internet côté crawl.
Et en 2026, le game a clairement changé. Google a lancé Google-Agent, un robot d’intelligence artificielle qui ne se contente plus de lire tes pages : il clique, navigue et remplit tes formulaires. Les bots de ChatGPT, Perplexity et Claude passent sur les sites stratégiques presque tous les jours. Si tu ne sais pas ce qui se passe dans tes logs, tu pilotes à l’aveugle. Voici comment y voir clair.
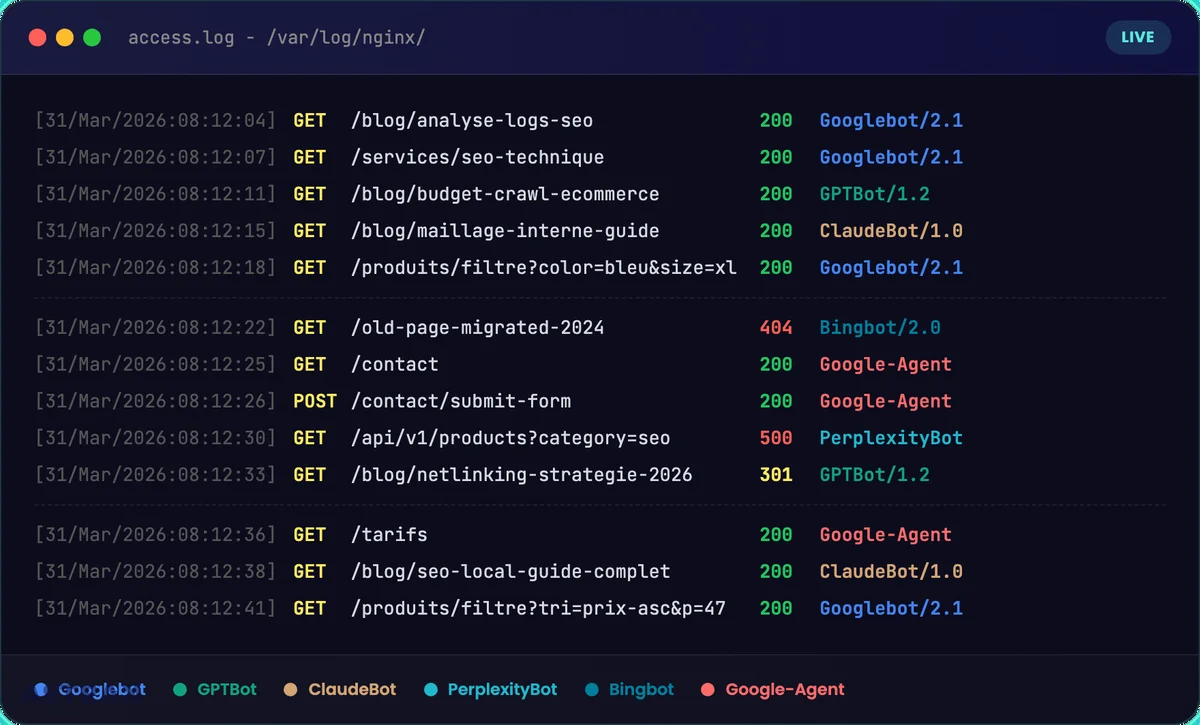
Qu’est-ce qu’un fichier log serveur et pourquoi le lire ?
Un fichier log (ou fichier journal), c’est un document texte généré automatiquement par ton serveur web (Apache, Nginx, IIS). Chaque fois qu’un visiteur – humain ou robot – envoie une requête à ton site internet, le serveur enregistre une ligne avec ces informations :
- L’adresse IP du visiteur
- La date et l’heure exactes de la requête
- L’URL demandée
- Le code de réponse HTTP (200, 301, 404, 500…)
- Le user-agent (l’identité du robot ou du navigateur)
- Le temps de réponse du serveur (TTFB)
Concrètement, une ligne de log ressemble à ça :
66.249.66.1 - - [31/Mar/2026:10:15:32] "GET /blog/article-seo HTTP/1.1" 200 45231 "Googlebot/2.1"
La différence avec les outils classiques est fondamentale. Google Analytics repose sur du JavaScript côté client : si le script est bloqué (adblocker, erreur de chargement), la visite n’est pas comptée. Et surtout, les robots ne déclenchent pas JavaScript. La Google Search Console fournit des données échantillonnées et agrégées avec plusieurs jours de retard.
Les logs serveur, c’est la seule source de vérité exhaustive. Tu vois en temps réel qui accède à quoi, quand, et avec quel résultat. Pour un consultant seo ou une agence seo, c’est la data la plus fiable qui existe pour comprendre le comportement des moteurs de recherche sur un site web. C’est une aide précieuse pour toute stratégie seo orientée résultats.
Quels robots explorent votre site en 2026 ?
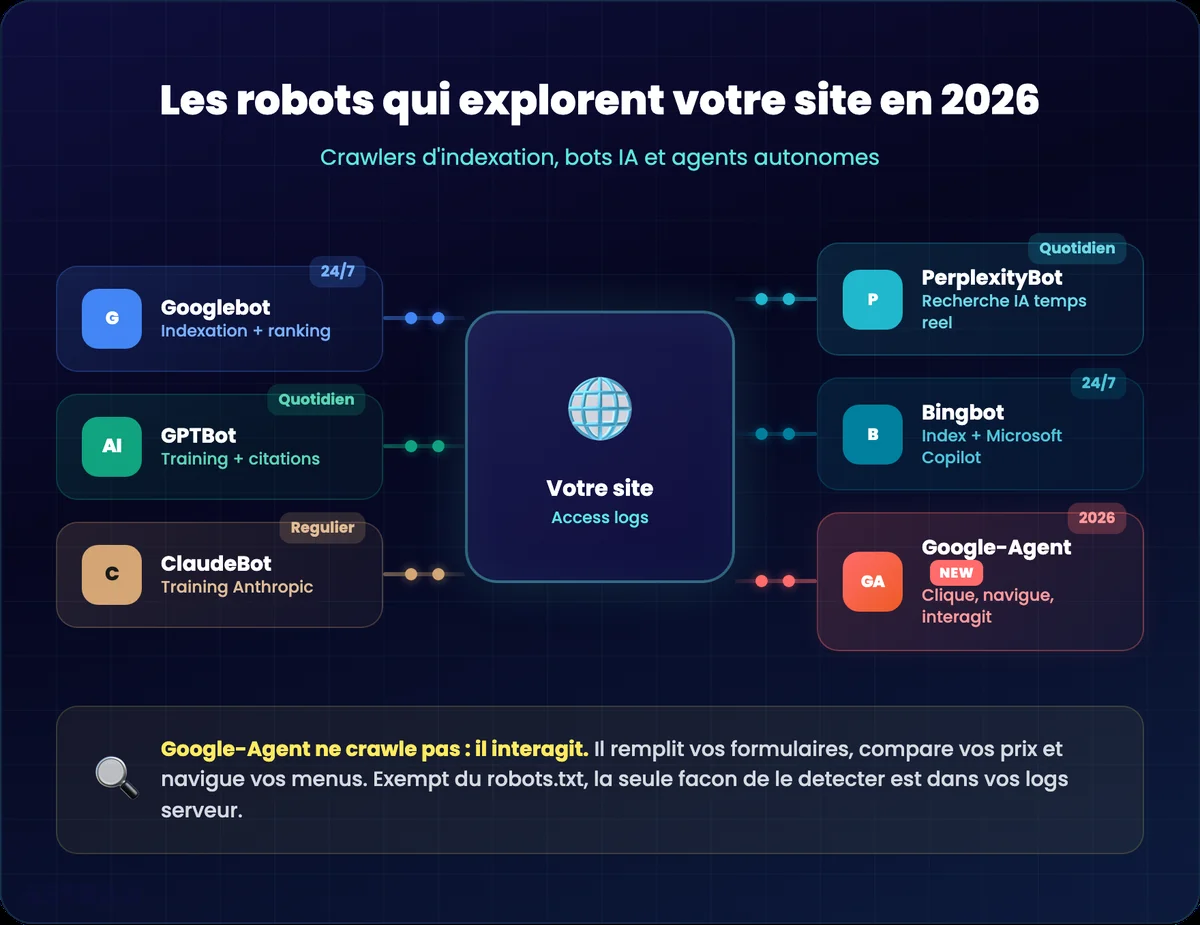
Googlebot et les crawlers d’indexation classiques
Googlebot reste le bot principal à surveiller pour le référencement naturel. Il existe en deux versions : Googlebot Desktop et Googlebot Mobile (smartphone). Depuis le passage au mobile-first indexing, c’est la version mobile qui fait référence pour l’exploration et l’indexation de tes pages web.
À côté de Googlebot, tu retrouves Bingbot (pour Bing et Microsoft Copilot), Yandex Bot, et les crawlers de Screaming Frog ou Ahrefs qui simulent le crawl seo. Chacun a sa propre fréquence de crawl et son propre comportement. Les identifier dans tes fichiers log, c’est la base de toute analyse de logs seo.
Les bots IA : GPTBot, ClaudeBot, PerplexityBot
C’est la grosse tendance de 2026. Les modèles d’intelligence artificielle envoient leurs propres robots pour nourrir leurs bases de connaissances. Dans tes logs, tu peux maintenant repérer :
- GPTBot (OpenAI) : crawle pour l’entraînement des modèles et les citations dans ChatGPT
- ClaudeBot (Anthropic) : collecte des données pour Claude
- PerplexityBot : alimente le moteur de recherche IA Perplexity
- Bingbot joue aussi un double rôle : indexation classique + alimentation de Microsoft Copilot
Ce qui est intéressant, c’est que les comportements diffèrent selon le type de crawl. Un bot IA dédié à l’entraînement (training) ne visite pas les mêmes pages qu’un bot dédié aux citations en temps réel. En isolant chaque crawler dans ton outil d’analyse, tu peux comparer ces comportements et comprendre lesquels de tes contenus sont exploités par les LLM.
Certains bots d’IA visitent les sites stratégiques presque quotidiennement. Si ton contenu est de qualité et bien structuré, il y a de fortes chances qu’il soit déjà ingéré par ces modèles. Les logs te le confirment noir sur blanc.
Google-Agent : le robot qui interagit avec votre site
Mars 2026, Google a ajouté un nouveau user-agent à sa documentation officielle : Google-Agent. Et là, on est sur quelque chose de radicalement différent.
Google-Agent est lié au Project Mariner. Ce n’est ni un crawler d’indexation (comme Googlebot), ni un crawler d’entraînement IA (comme Google-Extended). C’est un agent IA qui navigue et interagit avec ton site pour accomplir une tâche au nom d’un utilisateur. Concrètement, il clique sur tes boutons, parcourt tes menus, remplit tes formulaires de contact, compare tes prix et lit tes avis. Exactement comme un visiteur humain, mais en quelques secondes.
On passe de deux types de visiteurs (humains + crawlers) à trois types : humains, crawlers et agents IA. Et ça change tout pour le SEO technique.
Point important : en tant que « user-triggered fetcher », Google-Agent est exempté des règles robots.txt. Tu ne peux pas le bloquer comme un bot classique. La seule façon de savoir ce qu’il fait sur ton site, c’est de lire tes logs.
Léo en parle en détail dans ce post LinkedIn : les implications pour le SEO sont massives. Un site dont les formulaires sont mal codés, dont les boutons n’ont pas de labels clairs, ou dont la navigation est un labyrinthe va tout simplement être ignoré par l’agent IA au profit d’un concurrent mieux structuré. C’est le même shift qu’en 2015 avec le mobile : les sites qui ne sont pas « agent-friendly » vont commencer à perdre des opportunités.
Pourquoi faire une analyse de logs SEO ?
Optimiser le budget de crawl
Google attribue à chaque site un budget de crawl : un nombre limité de requêtes qu’il va consacrer à l’exploration de tes pages. Sur un site mal optimisé, jusqu’à 60% de ce budget peut être gaspillé sur des URL dupliquées, des pages de filtres e-commerce, des paramètres d’URL inutiles ou des spider traps (boucles infinies).
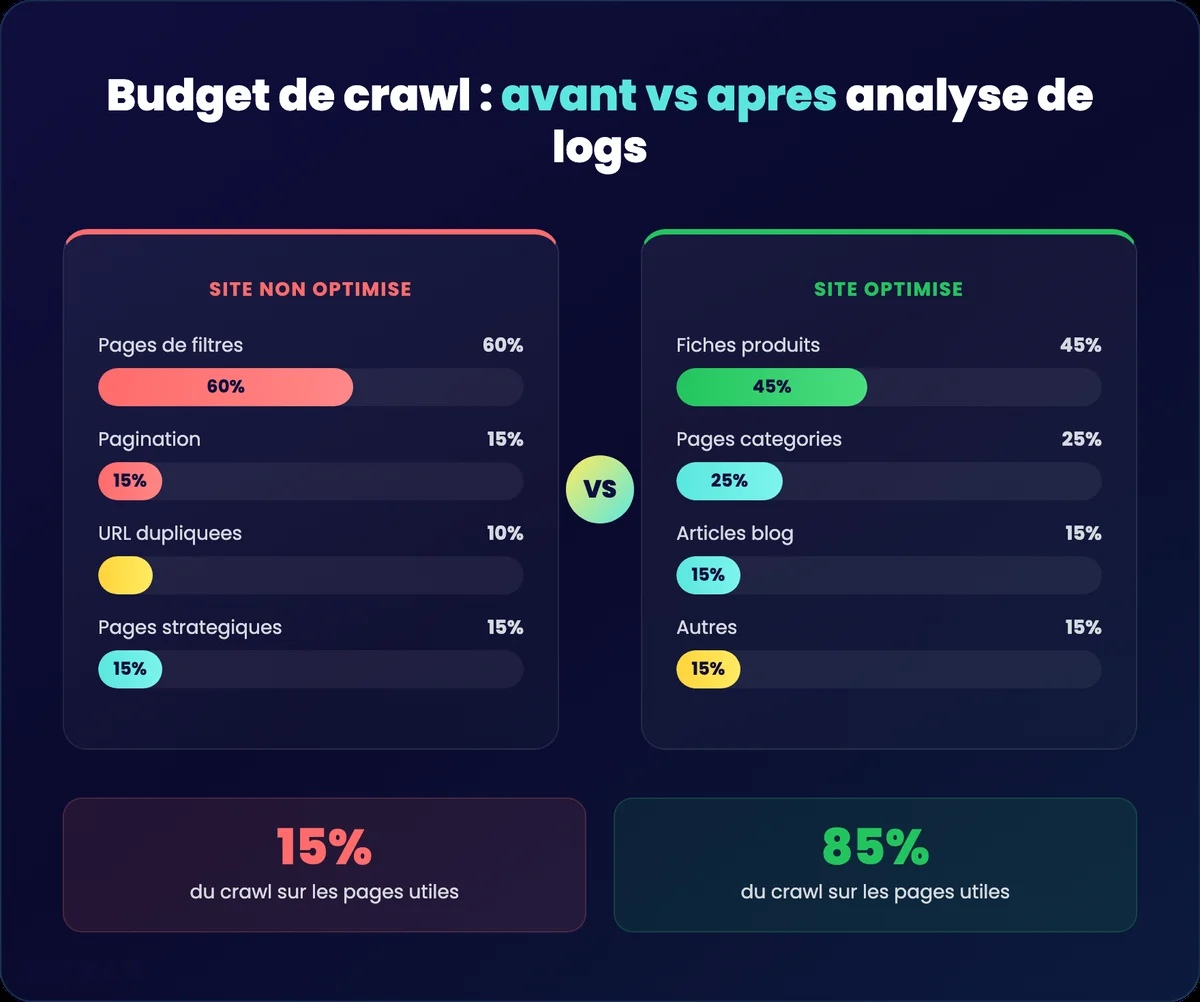
L’analyse des logs te montre exactement où Google passe son temps. Prenons un exemple concret : un site e-commerce avec 50 000 produits et 200 combinaisons de filtres par catégorie. Les logs révèlent que Googlebot passe 70% de son temps sur les pages de filtres (tri par prix, par couleur, par taille) et seulement 15% sur les fiches produits. Les 15% restants ? Des pages de pagination. Résultat : tes fiches produits stratégiques reçoivent 50 visites de bot par jour alors que tes filtres en reçoivent 10 000. Sans les logs, tu ne vois jamais ça.
L’objectif : viser 80% du crawl sur des pages qui génèrent du trafic organique. Pour y arriver, tu vas identifier dans les logs les sources de gaspillage (facettes, paramètres, spider traps) et les traiter via robots.txt, meta noindex ou canonical tags.
Pour les sites e-commerce à forte volumétrie, la gestion du budget de crawl est clairement un levier business direct. Un temps de réponse du serveur rapide (TTFB bas) favorise un meilleur passage des robots – c’est un indicateur technique à surveiller dans tes logs. Un TTFB supérieur à 500ms ralentit le crawl : Google envoie moins de requêtes pour ne pas surcharger ton serveur. Résultat, tes nouvelles pages mettent des semaines à être indexées.
Détecter les erreurs techniques invisibles
Les erreurs 4xx et 5xx sur des pages importantes sont des tueurs silencieux. Une erreur 500 intermittente sur ta page d’accueil ? Google Analytics ne te le dira pas. La Search Console te le signalera peut-être dans 3 jours. Tes logs te le montrent en temps réel.
Les codes de réponse prioritaires à identifier :
- 404 sur des pages qui reçoivent des backlinks (perte de jus SEO)
- 500/503 intermittentes (le serveur plante sous la charge du crawl)
- 301 en chaîne (redirections qui s’enchaînent et diluent l’autorité)
- Soft 404 (pages qui renvoient un code 200 mais affichent un contenu vide)
Repérer les pages orphelines et ignorées
Un contenu stratégique qui n’est jamais crawlé par Google ou les IA, c’est un contenu qui n’existe pas pour les moteurs de recherche. L’analyse de logs révèle ces pages ignorées, ce qui signale souvent un problème de maillage interne : aucun lien ne pointe vers elles, donc les robots ne les trouvent pas.
Concrètement, tu peux avoir un article de blog à forte valeur ajoutée, optimisé sur un mot-clé stratégique, mais si aucune page de ton site ne fait de lien vers cet article, Googlebot ne le trouvera peut-être jamais. Il apparaît dans ton sitemap, mais Google ne crawle pas systématiquement toutes les URL du sitemap. Le maillage interne reste le signal le plus fort pour guider l’exploration des robots.
À l’inverse, tu peux découvrir que des pages orphelines (non liées dans ton architecture) sont quand même crawlées grâce à des backlinks externes. C’est utile à savoir : ça signifie que ces pages ont de l’autorité entrante que tu pourrais mieux redistribuer. Les données de logs croisées avec un crawl Screaming Frog te donnent une vision complète de ton analyse web : d’un côté les pages que Google visite, de l’autre les pages que ton architecture propose. La différence entre les deux, c’est ton plan d’action.
Surveiller le crawl agressif et la charge serveur
Certains bots crawlent de manière agressive et peuvent surcharger ton serveur web. Un pic de requêtes inhabituel – par exemple un bot IA qui envoie 50 000 requêtes en une heure – peut ralentir ton site pour les vrais utilisateurs et dégrader ton temps de chargement.
Les logs te permettent d’identifier ces pics, de savoir quel bot en est responsable, et d’agir : ajuster le crawl-delay dans ton robots.txt, contacter l’opérateur du bot, ou renforcer ton infrastructure d’hébergement.
Mesurer l’impact réel d’une migration ou refonte
Lors d’une migration de site ou d’une refonte technique, les logs fournissent une donnée brute et factuelle sur le passage des robots. Tu vois en direct si Googlebot découvre les nouvelles URL, si les redirections fonctionnent, si des erreurs apparaissent sur les anciennes adresses.
Exemple typique : tu migres 500 URL d’un ancien CMS vers WordPress. Dans les 48 heures qui suivent la mise en place, tes logs te montrent exactement combien de ces 500 nouvelles URL ont été crawlées, si les 301 renvoient bien vers les bonnes destinations, et si des anciennes URL génèrent des 404. Sans les logs, tu attends 2 à 3 semaines que la Search Console te remonte les erreurs – et pendant ce temps, tu perds du trafic organique.
Contrairement aux outils tiers qui prennent des jours à refléter les changements, les fichiers log te donnent un retour immédiat. Pour les spécialistes seo qui gèrent des mises à jour techniques, c’est un outil indispensable de prise de décision.
Au fond, l’objectif de l’analyse de logs, c’est de faciliter la « digestion » de l’information par les moteurs et les IA. Chaque requête que Google envoie sur ton site a un coût de calcul. Plus tu lui facilites le travail (pages rapides, architecture claire, pas de gaspillage), plus il consacre son budget aux pages qui comptent pour ton business. C’est la même logique pour les bots IA : un site bien structuré, avec du contenu accessible et des données propres, sera mieux exploité par les modèles d’intelligence artificielle.
Comment faire une analyse de logs SEO étape par étape ?
Étape 1 : Récupérer les access logs du serveur
Les fichiers log se trouvent sur ton serveur web. Sur Apache, ils sont généralement dans /var/log/apache2/access.log. Sur Nginx, dans /var/log/nginx/access.log. Si tu es sur un hébergement mutualisé, tu devras les demander à ton hébergeur ou à ton administrateur système.
Récupère au minimum 30 jours de logs pour avoir un échantillon représentatif. Pour un audit seo complet, 3 mois de données permettent d’identifier les tendances saisonnières et les changements de comportement des bots.
Attention au format : vérifie que tes logs contiennent bien le user-agent (identifie le robot), le code de réponse HTTP et le temps de réponse. Sans ces informations, l’analyse perd une grande partie de sa valeur ajoutée.
Étape 2 : Importer dans un outil spécialisé
On ne va pas se mentir : analyser des logs bruts dans un éditeur texte, c’est possible mais pas très utile pour la plupart des projets. L’utilisation d’un outil d’analyse dédié te fait gagner un temps considérable.
Screaming Frog Log File Analyser est l’outil recommandé pour la majorité des cas. Tu crées un nouveau projet, tu glisses-déposes tes fichiers de logs dans l’interface, et l’outil structure toutes les données automatiquement. À 129 euros par an, le rapport qualité-prix est clairement le meilleur du marché.
Pour les sites à plus faible volumétrie, Seolyzer (outil français, à partir de 39 euros/mois) est une alternative efficace avec de nombreuses fonctionnalités intéressantes. Pour les très gros budgets et les sites e-commerce massifs, Oncrawl est considéré comme l’un des meilleurs outils seo pour croiser les données de crawl et de logs.
Étape 3 : Filtrer et vérifier les user-agents
Étape critique. Dans ton outil, filtre les user-agents pour choisir spécifiquement les robots que tu veux analyser : Googlebot, Bingbot, GPTBot, Google-Agent.
Et surtout : coche l’option « Verify Bots When Importing Logs » (dans Screaming Frog Log File Analyser). Pourquoi ? Parce qu’un grand nombre de bots spam usurpent l’identité de Googlebot. Sans vérification, tu analyses du faux trafic et tes résultats sont complètement biaisés.
Comment ça fonctionne concrètement ? L’outil effectue un reverse DNS lookup sur l’adresse IP du bot. Si la requête prétend venir de Googlebot mais que l’IP ne correspond pas aux plages officielles de Google (crawl-*.googlebot.com), c’est du spam. Cette vérification est indispensable : sur certains sites, jusqu’à 30% des requêtes identifiées comme « Googlebot » sont en réalité des faux bots qui polluent les données. Imagine les décisions que tu prendrais sur de la fausse data.
Pour les bots IA (GPTBot, ClaudeBot, PerplexityBot), la vérification est plus récente mais tout aussi utile. OpenAI et Anthropic publient leurs plages IP officielles, ce qui permet de distinguer les vrais crawlers des scrapers qui usurpent leur identité.
Étape 4 : Analyser robot par robot
L’erreur classique, c’est de regarder toutes les données agrégées. En isolant chaque crawler individuellement, tu peux comparer les comportements :
- Googlebot Mobile vs Desktop : est-ce que la version mobile crawle les mêmes pages ?
- GPTBot vs Googlebot : est-ce que l’IA s’intéresse aux mêmes contenus que le moteur de recherche ?
- Google-Agent : quelles pages interagissent avec cet agent ? Quels formulaires essaie-t-il de remplir ?
- Bots de training vs bots de citation : les données montrent des comportements très différents
Un cas concret qu’on voit souvent chez nos clients : GPTBot crawle massivement les articles de blog (contenus longs, informatifs, riches en données) mais ignore les pages commerciales. Googlebot, lui, fait l’inverse – il passe plus de temps sur les pages transactionnelles. En croisant les deux, tu comprends que ton contenu informationnel alimente les IA tandis que tes pages business alimentent l’index classique. Deux stratégies de référencement distinctes, visibles uniquement dans les logs.
Cette granularité est ce qui fait la valeur ajoutée d’une analyse de logs seo par rapport à un simple audit technique classique.
Étape 5 : Exploiter les rapports clés
Une fois les données structurées, concentre-toi sur ces rapports :
Overview (vue d’ensemble) : surveille le volume de crawl global et les courbes d’activité jour par jour. Un changement brutal (hausse ou baisse) signale une anomalie à investiguer – une mise à jour algorithmique, un problème serveur ou un changement dans ton robots.txt.
URLs les plus crawlées : identifie quelles pages les robots visitent le plus. Si tes pages de filtres e-commerce reçoivent plus de crawl que tes fiches produits, ton budget de crawl est mal réparti. À l’inverse, repère les contenus stratégiques jamais crawlés.
Codes de réponse : cherche les erreurs 4xx et 5xx sur des pages importantes. Une page qui renvoie un code 404 ou 500 au bot, c’est du contenu invisible pour l’indexation et pour l’entraînement des modèles IA.
Crawl agressif : identifie les pics de requêtes inhabituels. Un bot qui envoie un nombre massif de requêtes en peu de temps peut dégrader les performances de ton site pour les vrais utilisateurs. Par exemple, certains bots IA envoient des rafales de requêtes sans respecter de crawl-delay. Dans les logs, ça se voit immédiatement : 5 000 requêtes en 10 minutes depuis la même IP. Si ton serveur web n’est pas dimensionné pour absorber cette charge, le temps de chargement explose pour tout le monde.
Quels outils utiliser pour analyser les logs SEO ?
| Outil | Prix | Points forts | Pour qui ? |
|---|---|---|---|
| Screaming Frog Log File Analyser | 129 euros/an | Meilleur rapport qualité-prix, vérification des bots, interface claire | PME, agences, consultants |
| Seolyzer | 39 euros/mois | Outil français, monitoring en temps réel, nombreuses fonctionnalités | Sites à volumétrie moyenne |
| Oncrawl | Sur devis | Croisement données crawl + logs, SaaS complet, machine learning | E-commerce, grands sites |
| Botify | Sur devis | Suite complète, historique long, analyse de données avancée | Grands comptes, entreprises |
| ELK Stack | Open source | Aucune limite de volume, personnalisation totale | Sites massifs (8M+ pages), équipes techniques |
Screaming Frog Log File Analyser reste le choix par défaut pour la plupart des projets. Son gros avantage : la vérification des bots intégrée, le croisement avec les données de crawl Screaming Frog (tu importes ton crawl et tes logs dans le même outil), et une interface qui te sort des rapports exploitables en quelques clics. Pour 129 euros par an, c’est clairement un no-brainer.
Seolyzer se distingue par son monitoring en temps réel : tu connectes tes logs et tu vois le crawl en direct, sans attendre un import batch. C’est un outil français, bien maintenu, avec une approche « plug and play » qui convient aux sites à volumétrie moyenne. Le dashboard est intuitif et les alertes de crawl agressif sont un vrai plus.
Oncrawl est la solution pour les gros sites e-commerce. Sa force : le croisement automatique entre données de crawl, logs et analytics. Tu peux segmenter tes pages par type (fiches produits, catégories, blog), par profondeur, par nombre de liens internes, et voir les métriques de crawl pour chaque segment. Le machine learning intégré identifie des patterns que tu ne verrais pas manuellement. C’est un investissement, mais pour les sites avec des centaines de milliers de pages, la prise de décision est bien plus rapide.
Pour les sites à très forte volumétrie (plusieurs millions de pages), les outils classiques sur Excel ou logiciels desktop ne suffisent pas toujours. Des méthodes en ligne de commande Linux (grep, awk, sed) ou des solutions comme ELK Stack (Elasticsearch + Logstash + Kibana) permettent de traiter la masse de données sans limitation. C’est plus technique à mettre en place, mais c’est un outil puissant pour les équipes marketing et techniques qui ont besoin d’une analyse de données à grande échelle. Sur un site de 8 millions de pages, un Screaming Frog va ramer – ELK Stack ingère les logs en continu sans broncher.
À quelle fréquence analyser les logs SEO ?
La fréquence dépend de la taille de ton site et de tes objectifs. Voici ce qu’on recommande chez Astrak :
- Petit site vitrine : 1 analyse par an minimum, idéalement lors d’un audit seo annuel
- Site e-commerce ou média : tous les trimestres, voire tous les semestres. Le volume de pages et les mises à jour fréquentes justifient un suivi plus rapproché
- Après une migration ou refonte : analyse systématique dans les jours qui suivent la mise en place. C’est non négociable
- En cas d’anomalie d’indexation : dès que tu constates une chute de trafic inexpliquée ou des problèmes dans la Search Console, les logs te donnent la réponse
- Pour le suivi des bots IA : au minimum tous les 6 mois. Avec l’émergence de Google-Agent, GPTBot et les autres, il faut surveiller régulièrement comment ces nouveaux robots interagissent avec votre site
Sur des structures massives (exemple : 8 millions de pages), l’analyse de logs peut prendre plusieurs semaines de travail. Mais c’est indispensable pour optimiser le budget de crawl et s’assurer que Google ne s’épuise pas sur des pages inutiles.
Un point important : avec l’arrivée de Google-Agent et des bots IA, la fréquence d’analyse va mécaniquement augmenter. Ces nouveaux robots changent de comportement à chaque mise à jour de leurs modèles. GPTBot ne crawlait pas les mêmes pages en janvier 2026 qu’en mars 2026. Suivre cette évolution, c’est comprendre comment ton contenu est perçu et exploité par les IA – un enjeu de visibilité qui n’existait pas il y a deux ans.
L’analyse de logs SEO transforme des intuitions en données actionnables. L’intérêt est clair : que tu cherches l’optimisation de ton référencement naturel, à comprendre comment les IA exploitent ton contenu, ou à détecter des problèmes techniques que tes outils classiques ne voient pas, les fichiers journaux de ton serveur contiennent les réponses. Il suffit de les lire.
Prêt à propulser votre
visibilité sur Google?
Commence par un audit SEO gratuit et découvre ton potentiel de croissance
Prendre Rendez-vous